Using AI in Vulnerability Analysis - Part 3 (Performance Analysis)
tl;dr: Chat GPT-4o and Gemini 2.0 Flash demonstrate 90% agreement with human analysis in vulnerability analysis.
In this article, I will compare the performance of 3 AI models in categorizing 50 vulnerabilities. The vulnerabilities will be classified into Operating System (OS) vulnerabilities, where the OS is vulnerable and Non Operating System (Non-OS) vulnerabilities where the vulnerable component is not an operating system. This article follows two other articles where we compared the applicability of off the shelf AI tools i.e., ChatGPT's custom GPTs and easily accessible AI APIs. The first two articles were integral in identifying how to apply AI in solving the task above and this article explores the performance of the models.
Methodology
i. Model Selection
Currently there are very many LLMs to choose from. For this task, I avoided reasoning models and picked 3 models from the top AI providers Google, OpenAI and Meta. Those are -
a. Gemini 2.0 Flash
b. Chat GPT 4-o
c. Llama 3.3 70b
For Gemini and ChatGPT, I made use of Gemini's Developer API and OpenAI's developer platform API. I accessed Llama via groq.com.
ii. Obtaining Sample Data
The sample data was a random selection of 50 vulnerabilities from CISA's Known Exploited Vulnerabilities Database (KEVD).

iii. Prompt Engineering
While designing the prompt, I utilized the few shot approach with a clear role definition and clear output formatting instructions. I used a temperature of 0.0 for a more deterministic output.
Prompt:
Below is a vulnerability description taken from the NIST NVD Database. I would like you to analyse the vulnerability and return either 'OS' if, based on the description the vulnerability affects an Operating System or, 'Non-OS', if, based on the description the vulnerability does not affect an operating system. For example, a vulnerability that affects a web application would be classified as 'Non-OS' while a vulnerability that affects a Linux Kernel would be classified as 'OS'. In another case, a vulnerability that affects a Windows Service would be classified as 'OS' while a vulnerability that affects a desktop application would be classified as 'Non-OS'.
iv. Automated Analysis Using Python
The code I wrote while working on this article can be found on my Github Page
Working via the API
Making use of the APIs required a programatic approach, therefore, I wrote a script that fetches the vulnerability description and appends it to the prompt. The script then collects the output for each vulnerability description and creates a new worksheet with the analysis.
Below is sample output from each of the models, given the same prompt:
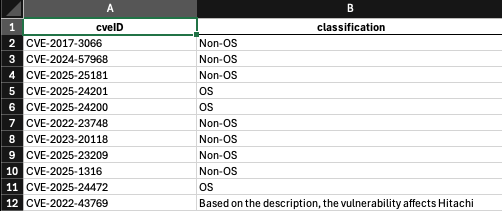
Apart from the item on the 12th row, the rest of the results conformed with the output formatting instructions.
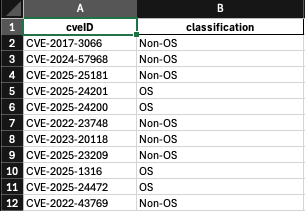
Gemini 2.0 Flash did not deviate from the output instructions.
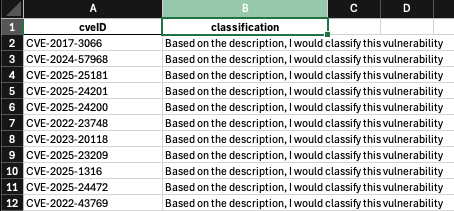
Llama on the other hand completely deviated from the instructions. Given that I had a to restrict the number of output tokens, I decided not to change the prompt for the sake of one model as I received the expected results from the two other models additionally, there were time constraints.
v. Analyzing the Output
Once I had the raw output, I went ahead to manually analyze the vulnerabilities and I put down my findings in a separate worksheet. I then generated an additional script that compared my analysis with the output provided by each model where my analysis was treated as the ground truth. The script calculated the following:
- Comprehensive performance metrics (accuracy, precision, recall, F1 score)
- Detailed disagreement analysis
- Visual highlighting of disagreements in the Excel file
- Comparison charts and confusion matrices
Results
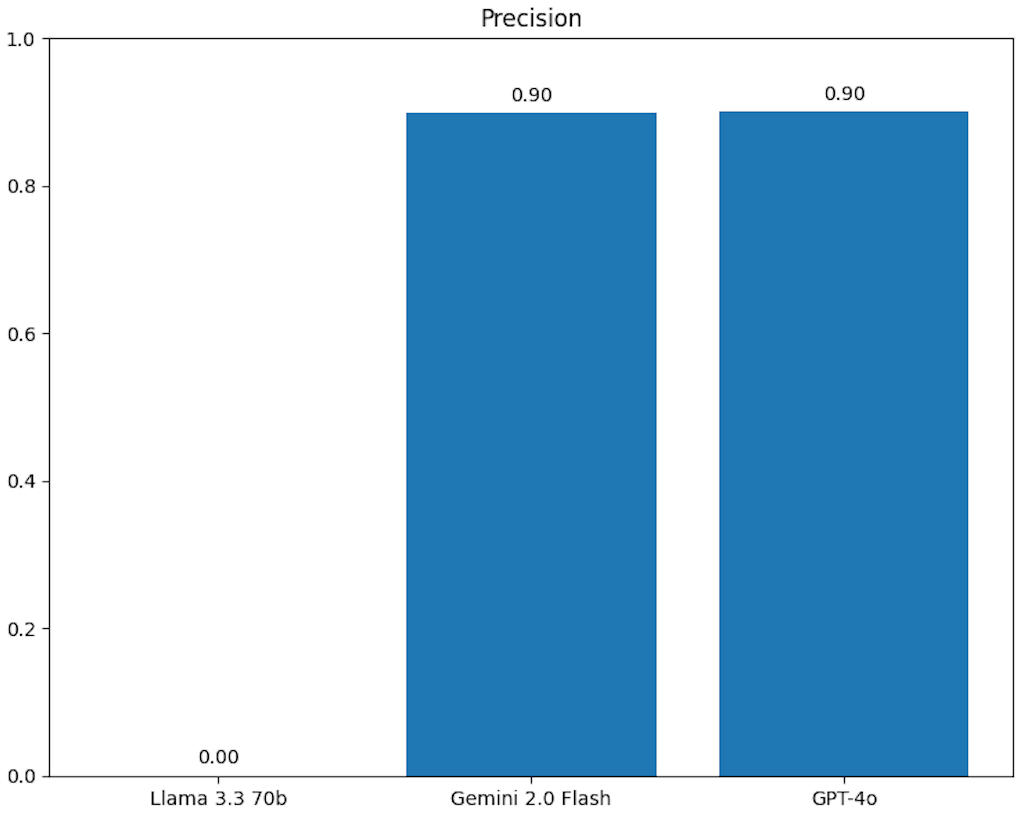
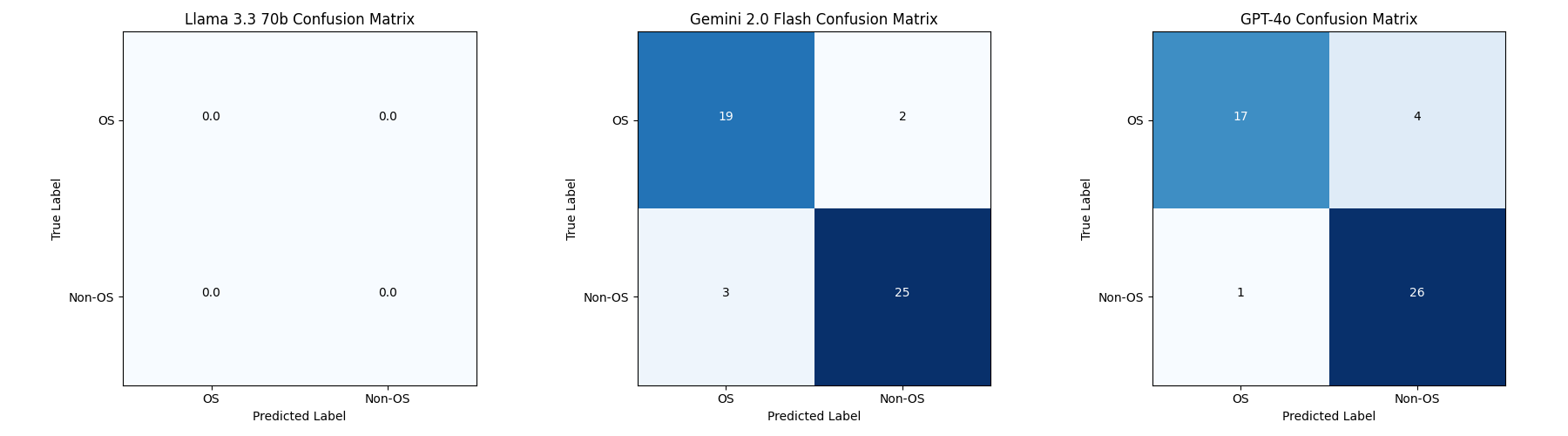
Out of the results generated by the script, I focused on the disagreement analysis on Excel and the precision.
The disagreement analysis revealed that Gemini and ChatGPT disagreed on different vulnerabilities, which was quite interesting. Based on the results, I noted that a potential improvement would be to define "operating system" in the prompt to prevent inaccuracies, such as Gemini's misclassification of VMware's ESXi as an OS instead of a hypervisor (Non-OS).
I would highly recommend checking out the disagreement analysis on my on the "Detailed Comparison" Worksheet. Below is the precision and confusion matrix from the analysis.
Conclusion
To briefly conclude, I would say that LLMs can definitely be used to handle menial vulnerability analysis/enrichment tasks with acceptable accuracy as long as strong prompt engineering and repeated testing is done